
Blog

-
6 minutes
read
Managing cloud costs while maintaining system reliability is a complex challenge. This post delves into how chaos engineering can help organizations optimize their cloud environments, offering actionable insights and strategies to achieve significant cost savings while ensuring robust system performance.
Managing cloud costs while ensuring system reliability is a crucial challenge for many organizations. Chaos engineering, a practice of intentionally disrupting systems to test their resilience, can significantly improve cost efficiency in cloud environments. This blog post explores how to leverage chaos engineering to reduce cloud costs, drawing insights from three detailed posts on the subject.
Understanding the Benefits of Chaos Engineering
Chaos engineering is a proactive approach aimed at preventing system failures by identifying vulnerabilities before they cause significant outages. The primary challenge in measuring its benefits lies in quantifying the cost of prevented outages. However, the true value extends beyond mere prevention. By identifying and fixing bugs early in the development cycle, organizations can save significantly on engineering labor and reduce the opportunity costs associated with system failures.
1. Baseline Metrics and Costs:
Begin by capturing your baseline performance metrics, including mean time to detection (MTTD) and mean time to resolution (MTTR), and track high-severity incidents and infrastructure metrics, such as resource consumption and latency. Calculating the economic impact of past incidents can provide a comparative basis for the cost savings achieved through chaos engineering.
2. Tracking Issues:
Document every issue discovered through chaos engineering in your ticketing system. This documentation helps in proving the effectiveness of chaos engineering to management by showcasing the number of issues found and fixed.
Managed Clusters and Cost Optimization
Managed Kubernetes clusters offer a pay-as-you-go pricing model, which is excellent for scaling workloads but can lead to unexpected costs if not managed properly. Here’s how chaos engineering can help reduce these costs:
1. Capacity Planning and Right-Sizing:
The size of your cluster is the biggest cost driver. Start by analyzing your current CPU, RAM, and disk space usage to determine your minimum capacity requirements. Use chaos engineering to simulate high-stress conditions on your nodes to ensure they can handle resource constraints. This helps in identifying whether you can downscale to smaller, less expensive nodes without affecting performance.
2. Autoscaling Validation:
Chaos engineering can simulate increased resource consumption to trigger autoscaling, ensuring that your autoscaling rules are working as intended. This helps in maintaining an optimal balance between performance and cost.
3. Utilizing Preemptible Instances:
Preeptible instances offer significant cost savings but come with the risk of termination at any time. Chaos engineering can simulate the random termination of these instances to test whether your applications can handle such disruptions without data loss or service interruption. Successfully leveraging preemptible instances can reduce your cloud costs by up to 90%.
Cost-Benefit Analysis of Chaos Engineering
Determining the ROI of chaos engineering involves comparing the cost of potential outages to the costs of implementing chaos engineering practices. A simplified formula can help illustrate the benefits:
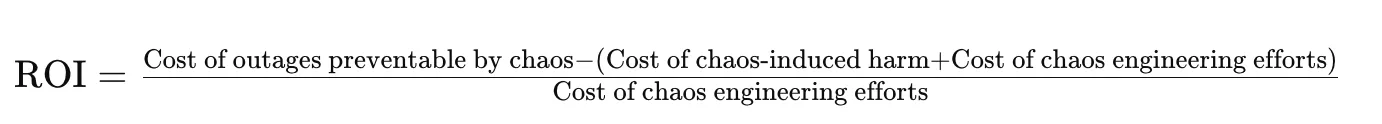
For example, if the cost of preventable outages is $500,000, the chaos-induced harm is $10,000, and the cost of implementing chaos engineering is $250,000, the ROI would be:
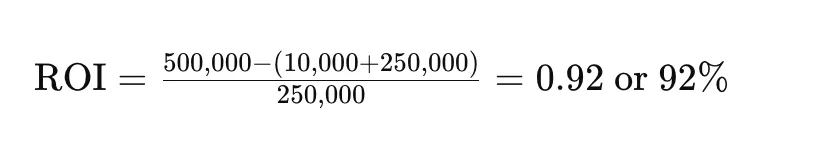
This means the capital employed for chaos engineering has a payback of 92%, indicating significant profitability and justifying the investment.
Implementing Chaos Engineering
1. Technical Tooling:
Implement tools that allow you to perform chaos experiments, such as slowing down CPU usage or affecting network traffic. Ensure you have the necessary infrastructure to document and analyze the results of these experiments.
2. Collaboration and Documentation:
Engage your teams in the chaos engineering process. Prepare experiments, inform relevant teams, and meticulously document errors and outcomes to ensure continuous improvement.
3. Vendor Solutions:
Consider using platforms like Steadybit, which can simplify the chaos engineering process by providing ready-to-use tools and frameworks, reducing the need for a dedicated chaos engineering team.
Wrapping Up
Chaos engineering is about understanding and improving your systems' resilience while optimizing costs. By integrating chaos engineering into your cloud strategy, you achieve significant cost savings, enhance system reliability, and ensure a robust infrastructure capable of handling unexpected disruptions.